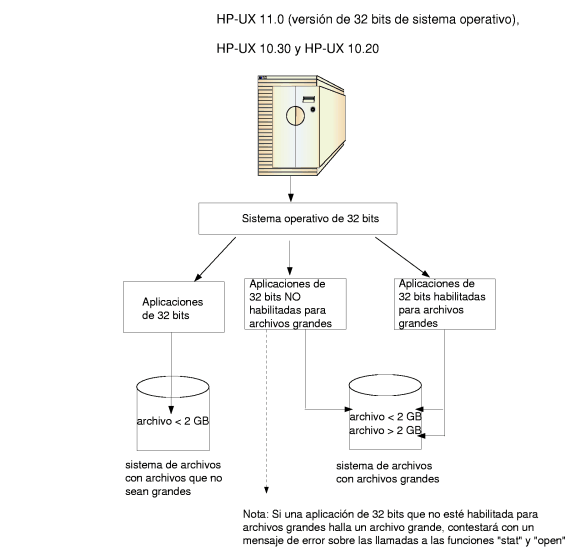
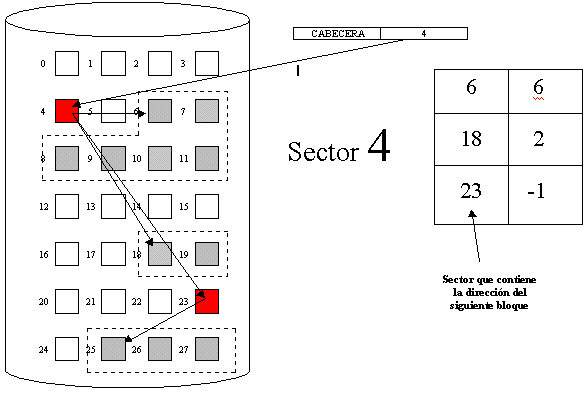
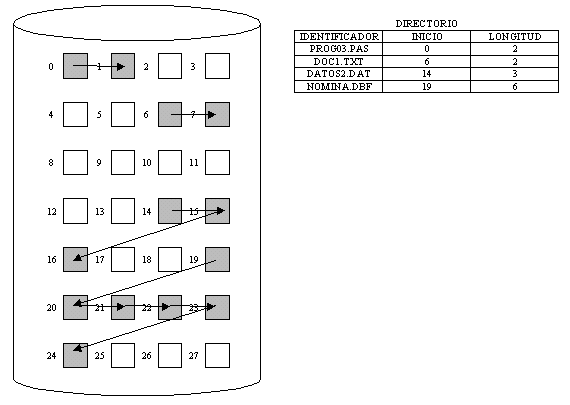
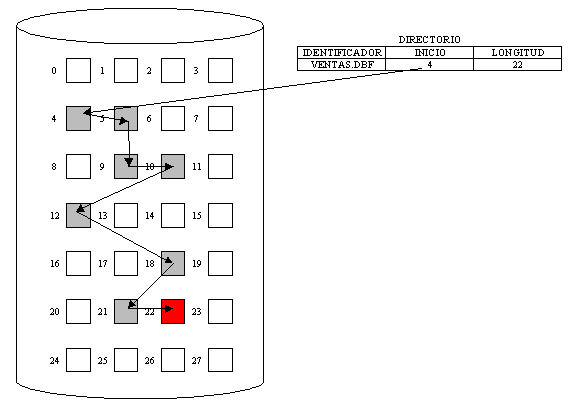
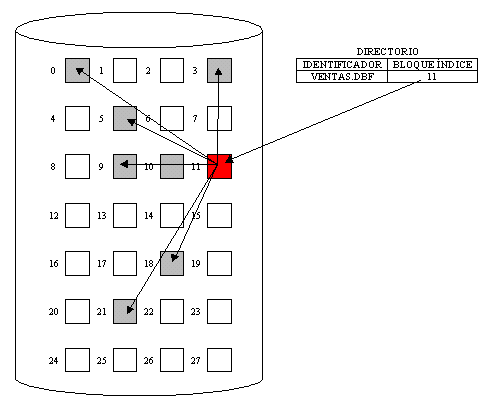
6.1 Concepto y objetivos de
protección.
La protección es un mecanismo control
de acceso de los programas, procesos o usuarios al sistema o recursos.
Hay importantes razones para proveer
protección. La más obvia es la necesidad de prevenirse de violaciones
intencionales de acceso por un usuario. Un recurso desprotegido no puede
defenderse contra el uso no autorizado o de un usuario incompetente. Los sistemas
orientados a la protección proveen maneras de distinguir entre uso autorizado y
desautorizado.
Objetivos
•
Inicialmente
protección del SO frente a usuarios poco confiables.
•
Protección:
control para que cada componente activo de un proceso solo pueda acceder a los
recursos especificados, y solo en forma congruente con la política establecida.
•
La mejora
de la protección implica también una mejora de la seguridad.
•
Las
políticas de uso se establecen:
•
Por el
hardware.
•
Por el
administrador / SO.
•
Por el
usuario propietario del recurso.
•
Principio
de separación entre mecanismo y política:
•
Mecanismo
→ con que elementos (hardware y/o software) se realiza la protección.
•
Política
→ es el conjunto de decisiones que se toman para especificar cómo se usan esos
elementos de protección.
•
La
política puede variar dependiendo
de la aplicación, a lo
largo del tiempo.
•
La
protección no solo es cuestión del administrador, sino también del usuario.
•
El
sistema de protección debe:
•
distinguir
entre usos autorizados y no-autorizados.
•
especificar
el tipo de control de acceso impuesto.
•
proveer
medios para el aseguramiento de la protección.
6.2 Funciones
del sistema de protección.
•
tener la flexibilidad
suficiente para poder imponer una diversidad de políticas y mecanismos.
•
Protección de los
procesos del sistema contra los procesos de usuario.
•
Protección de los
procesos de usuario contra los de otros procesos de usuario.
•
Protección de Memoria.
•
Protección de los
dispositivos.
6.3 Implantación
de matrices de acceso.
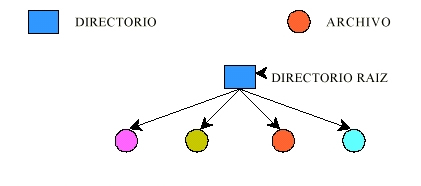
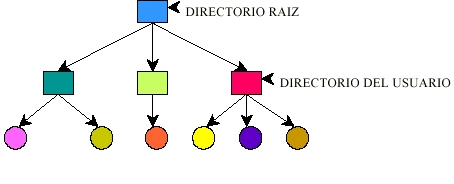
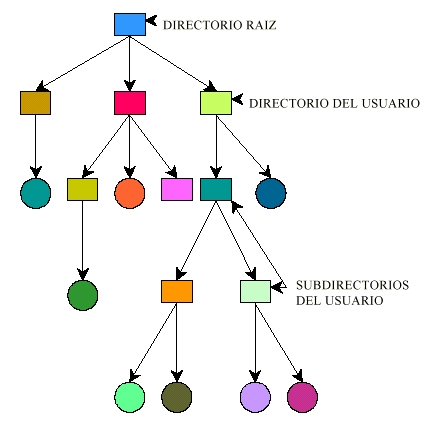
- Concretos:
- Ej.: discos, cintas, procesadores, almacenamiento, etc.
- Abstractos:
- Ej.: estructuras de datos, de procesos, etc.
Los objetos están
protegidos contra los sujetos.
Las autorizaciones a un sistema
se conceden a los sujetos.
Los sujetos pueden ser varios tipos de entidades:
- Ej.: usuarios, procesos, programas, otras entidades, etc.
Los derechos de acceso más comunes son:
- Acceso de lectura.
- Acceso de escritura.
- Acceso de ejecucion.
Una forma de
implementación es mediante una matriz de control de acceso con:
- Filas para los sujetos.
- Columnas para los objetos.
- Celdas de la matriz para los derechos de acceso que un usuario tiene a un objeto.
Una matriz
de control de acceso debe ser muy celosamente protegida por el S. O.
6.4 Protección
basada en el lenguaje.
A medida que ha
aumentado la complejidad de los sistemas operativos, sobre todo al trata de
ofrecer interfaces de más alto nivel con el usuario, lo objetivos de la
protección se han vuelto mucho más refinados. En esta refinación observamos que
los diseñadores de los diseñadores de los sistemas de protección se han apoyado
mucho en ideas que se originaron en los lenguajes de programación y
especialmente en los conceptos de tipos de datos abstractos y objetos. Los
sistemas de protección ahora se ocupan no sólo de la identidad de un recurso al
cual se intenta acceder, sino también de la naturaleza funcional de ese acceso.
En los sistemas de protección más nuevos, el interés en la función que se
invocará se extiende más allá de un conjunto de funciones definidas por el
sistema, como los métodos de acceso a archivos estándar, para incluir funciones
que también podrían ser definidas por el usuario.
Las políticas para el
uso de recursos también podrían variar, dependiendo de la aplicación, y podrían
cambiar con el tiempo. Por estas razones, la protección ya no puede
considerarse como un asunto que sólo concierne al diseñador de un sistema
operativo; también debe estar disponible como herramienta que el diseñador de
aplicaciones pueda usar para proteger los recursos de un subsistema de
aplicación contra intervenciones o errores.
Aquí es donde los
lenguajes de programación entran en escena. Especificar el control de acceso
deseado a un recurso compartido en un sistema es hacer una declaración acerca
del recurso. Este tipo de declaración se puede integrar en un lenguaje mediante
una extensión de su mecanismo de tipificación. Si se declara la protección
junto con la tipificación de los datos, el diseñado de cada subsistema puede
especificar sus necesidades de protección así debería darse directamente
durante la redacción del programa, y en el lenguaje en el que el programa mismo
se expresa. Este enfoque tiene varias ventajas importantes:
1. Las necesidades de
protección se declaran de forma sencilla en vez de programarse como una
secuencia de llamadas a procedimientos de un sistema operativo.
2. Las necesidades de
protección pueden expresarse independientemente de los recursos que ofrezca un
sistema operativo en particular.
3. El diseñador de un
subsistema no tiene que proporcionar los mecanismos para hacer cumplir la
protección.
4. Una notación
declarativa es natural porque los privilegios de acceso están íntimamente
relacionados con el concepto lingüístico de tipo de datos.
6.5 Concepto de
seguridad.
La seguridad informática es el área
de la informática que se enfoca en la protección de la infraestructura
computacional y todo lo relacionado con esta (incluyendo la información
contenida).. La seguridad informática comprende software, bases de datos,
metadatos, archivos y todo lo que la organización valore (activo) y signifique
un riesgo si ésta llega a manos de otras personas. Este tipo de información se
conoce como información privilegiada o confidencial.
El uso creciente y la confianza en
los computadores en todo el mundo ha hecho surgir una preocupación legítima con
respecto a la seguridad informática. El uso de los computadores ha extendido en
ambientes comerciales, gubernamentales, militares e incluso en los hogares.
Grandes cantidades de datos vitales sensibles se están confiando y almacenado
cada vez más en computadores. Entre ellos se incluyen registros sobre
individuos, negocios y diferentes registros públicos y secretos gubernamentales
y militares. Grandes transacciones monetarias tienen lugar diariamente en forma
de transferencia electrónicas de fondos. Más recientemente, informaciones tales
como notificaciones de propiedad intelectual y datos comerciales estratégicos
son también almacenados, procesados y diseminados mediante computadores. Entre
ellos se incluyen diseños de ventas, contratos legales y muchos otros.
La seguridad, no solo requiere un
sistema de protección apropiado, sino también considerar el entorno externo en
el que el sistema opera. La protección interna no es útil si la consola del
operador está al alcance de personal no autorizado, o si los archivos se pueden
sacar simplemente del sistema de computación y llevarse a un sistema sin
protección. Estos problemas de seguridad son esencialmente de administración,
no problemas del sistema operativo.
6.6
Clasificaciones de la seguridad.
Es decir que
la clasificación de los sistemas de computación según sus requerimientos de la
seguridad ha sido ampliamente discutida de la seguridad del sistema.
En esta
clasificación especifica, hay cuatro niveles de seguridad: a, b, c y d… a
continuación, se describen estos niveles de seguridad y las características de
cada uno.
Nivel D es el
Sistemas con protección mínima o nula no pasan las pruebas de seguridad mínima.
MS-DOS y Windows 3. 1 son sistemas de nivel d. Puesto que están pensados para
un sistema mono proceso y mono usuario, no proporcionan ningún tipo de control
de acceso ni de separación de recursos.
- Control de acceso por dominios.
- Control de acceso individualizado.
Nivel B es el
Control de acceso obligatorio en este nivel, los controles de acceso no son
discrecionales de los usuarios o los dueños de los recursos, que deben existir
obligatoriamente. Esto significa que todo objeto controlado debe tener
protección sea del tipo que sea. Es decir que son tres y son:
- Etiqueta de seguridad obligatoria.
- Protección estructurada.
- Y el dominio de seguridad.
Nivel A es el
Sistemas de seguridad certificados para acceder a este nivel, la política de
seguridad y los mecanismos de protección del sistema deben ser verificados y
certificados por un organismo autorizado para ello.es decir dos tipos:
- Diseño verificado.
- Desarrollo controlado.
Amenazas a
la seguridad en el acceso al sistema:
- Intrusos.
- Programas malignos.
Intrusos:
- Piratas o hackers: individuos que acceden al sistema sin autorización.
- Los sistemas presentan agujeros por donde los hackers consiguen colarse.
Técnicas de
intrusión:
- Averiguar contraseñas (más del 80% de las contraseñas son simples).
- Probar exhaustivamente.
- Descifrar archivo de contraseñas.
- Intervenir líneas.
- Usar caballos de Troya.
Técnicas de
prevención de intrusos:
Establecer
una buena estrategia de elección de contraseñas:
·
Contraseñas generadas por ordenador (difícil
memorización).
·
Inspección activa (proceso periódico de averiguación).
·
Inspección proactiva (decidir si es buena en su
creació
Tipos de
amenazas:
Amenazas
pasivas:
·
Revelación del contenido del mensaje.
·
Análisis del tráfico:
o
En caso de que los mensajes vayan encriptados.
o
Determinar las máquinas que se comunican y la frecuencia
y longitud de los mensajes.
Amenazas
activas:
·
Alteración del flujo de mensajes.
·
Privación del servicio:
·
Impide el uso normal de los servicios de
comunicaciones.
·
Suplantación:
o
Cuando una entidad finge ser otra diferente.
Clasificación
de programas malignos:
Programas
malignos que necesitan anfitrión:
Trampillas:
Bomba
lógica:
Caballo de
Troya:
Programas
malignos que no necesitan anfitrión:
Gusanos:
Bacterias:
Virus:
Algoritmo de virus muy simple
Algoritmo de virus muy simple
El cifrado es un método que permite
aumentar la seguridad de un mensaje o de un archivo mediante la codificación
del contenido, de manera que sólo pueda leerlo la persona que cuente con la
clave de cifrado adecuada para descodificarlo. Por ejemplo, si realiza una
compra a través de Internet, la información de la transacción (como su
dirección, número de teléfono y número de tarjeta de crédito) suele cifrarse a
fin de mantenerla a salvo. Use el cifrado cuando desee un alto nivel de
protección de la información.