5.1 Concepto de Sistema de archivos
Concepto 1:
Son los algoritmos y estructuras lógicas utilizadas para poder acceder a la información que tenemos en el disco. Cada uno de los sistemas operativos crea estas estructuras y logaritmos de diferente manera independientemente del hardware.
Concepto 1:
Son los algoritmos y estructuras lógicas utilizadas para poder acceder a la información que tenemos en el disco. Cada uno de los sistemas operativos crea estas estructuras y logaritmos de diferente manera independientemente del hardware.
El desempeño de nuestro disco duro, la confiabilidad, seguridad, capacidad de expansión y la compatibilidad, estará en función de estas estructuras lógicas.
Fat 12:
Es el sistema de archivos de DOS, y es con el que formateamos los disquetes. Fue muy utilizado en las primeras PCs.
Es el sistema de archivos de DOS, y es con el que formateamos los disquetes. Fue muy utilizado en las primeras PCs.
Fat 16:
Este sistema de archivos tenia muchas limitaciones, por ejemplo si el disco duro era mayor de 2 GB, era imposible particionarlos y no usaba nombre largos en los archivos, solo 8 caracteres.
Este sistema de archivos tenia muchas limitaciones, por ejemplo si el disco duro era mayor de 2 GB, era imposible particionarlos y no usaba nombre largos en los archivos, solo 8 caracteres.
Fat 32:
Fue utilizado a partir de 1997, y pudo ser utilizado en Windows 98, pero a medida que el tamaño de los discos duros se incrementaba, surgieron nuevas limitaciones. Se llamo Fat32, por que utiliza números de 32 bits para representar a los clusters en lugar de los 16 en los sistemas anteriores.
Fue utilizado a partir de 1997, y pudo ser utilizado en Windows 98, pero a medida que el tamaño de los discos duros se incrementaba, surgieron nuevas limitaciones. Se llamo Fat32, por que utiliza números de 32 bits para representar a los clusters en lugar de los 16 en los sistemas anteriores.
NTFS

Fig. 5.1.1 Archivos NTFS
Especialmente creado para usarlo en Windows NT, es mas complejo que los FAT. El propósito era satisfacer la demanda y necesidades de de seguridad y eficacia para servidores y otras aplicaciones en red. No tiene limitaciones de tamaño clusters y en general en el disco. Una ventaja de este sistema de archivos es que tiene un sistema antifragmentación.
Linux:

Fig. 5.1.2 Logo Linux
Este sistema de archivos trabaja de manera totalmente distinta, las particiones del disco se colocan en el directorio raíz. Podemos incluso tener diferentes particiones y cada una de ellas tener su propio sistema de archivos.
Concepto 2 :
En computación, un sistema de archivos es un método para el almacenamiento y organización de archivos de computadora y los datos que estos contienen, para hacer más fácil la tarea encontrarlos y accederlos. Los sistemas de archivos son usados en dispositivos de almacenamiento como discos duros y CD-ROM e involucran el mantenimiento de la localización física de los archivos.
En computación, un sistema de archivos es un método para el almacenamiento y organización de archivos de computadora y los datos que estos contienen, para hacer más fácil la tarea encontrarlos y accederlos. Los sistemas de archivos son usados en dispositivos de almacenamiento como discos duros y CD-ROM e involucran el mantenimiento de la localización física de los archivos.
Más formalmente, un sistema de archivos es un conjunto de tipo de datos abstractos que son implementados para el almacenamiento, la organización jerárquica, la manipulación, el acceso, el direccionamiento y la recuperación de datos. Los sistemas de archivos comparten mucho en común con la tecnología de las bases de datos.
Los sistemas de archivos pueden ser representados de forma textual (ej.: el shell de DOS) o gráficamente (ej.: Explorador de archivos en Windows) utilizando un gestor de archivos.
El software del sistema de archivos se encarga de organizar los archivos (que suelen estar segmentados físicamente en pequeños bloques de pocos bytes) y directorios, manteniendo un registro de qué bloques pertenecen a qué archivos, qué bloques no se han utilizado y las direcciones físicas de cada bloque.
Los sistemas de archivos pueden ser clasificados en tres categorías: sistemas de archivo de disco, sistemas de archivos de red y sistemas de archivos de propósito especial.
Ejemplos de sistemas de archivos son: FAT, UMSDOS, NTFS, UDF, ext2, ext3, ext 4, ReiserFS, XFS, etc.
Concepto 3 :
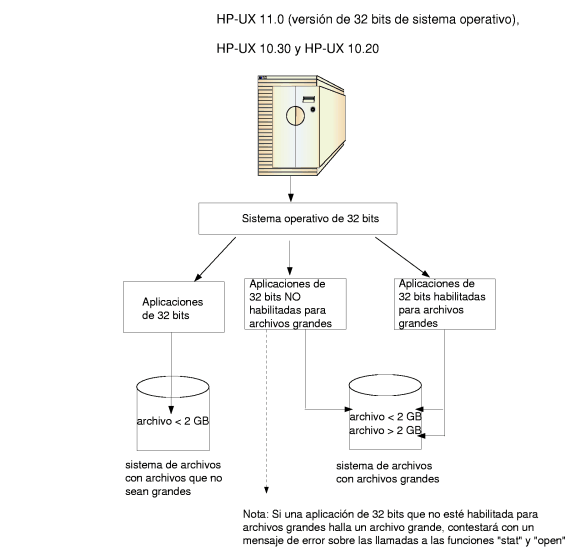
Fig. 5.1.3 Administración de archivos por el sistema operativo
Los archivos son administrados por el sistema operativo como se muestra en la Fig. 5.1.3. Su estructura, nombre, forma de acceso, uso, protección e implantación son temas fundamentales en el diseño de un sistema operativo. Aquella parte del sistema operativo que trabaja con los archivos se conoce, como un todo, como el sistema de archivos.
Los sistemas de archivos pueden ser representados de forma textual (ej.: el shell de DOS) o gráficamente (ej.: Explorador de archivos en Windows) utilizando un gestor de archivos.
El software del sistema de archivos se encarga de organizar los archivos (que suelen estar segmentados físicamente en pequeños bloques de pocos bytes) y directorios, manteniendo un registro de qué bloques pertenecen a qué archivos, qué bloques no se han utilizado y las direcciones físicas de cada bloque.
Los sistemas de archivos pueden ser clasificados en tres categorías: sistemas de archivo de disco, sistemas de archivos de red y sistemas de archivos de propósito especial.
Ejemplos de sistemas de archivos son: FAT, UMSDOS, NTFS, UDF, ext2, ext3, ext 4, ReiserFS, XFS, etc.
Concepto 3 :
Fig. 5.1.3 Administración de archivos por el sistema operativo
Los archivos son administrados por el sistema operativo como se muestra en la Fig. 5.1.3. Su estructura, nombre, forma de acceso, uso, protección e implantación son temas fundamentales en el diseño de un sistema operativo. Aquella parte del sistema operativo que trabaja con los archivos se conoce, como un todo, como el sistema de archivos.
Concepto 4 :
Debido a su importancia, es necesario que un sistema operativo tenga la capacidad de leer, escribir, acceder y mantener la integridad de un sistema de archivos. Un sistema de archivos provee al usuario con una abstracción que le permitirá crear con facilidad colecciones de datos llamados archivos. Estas colecciones deberán tener los siguientes requisitos o propiedades:
Debido a su importancia, es necesario que un sistema operativo tenga la capacidad de leer, escribir, acceder y mantener la integridad de un sistema de archivos. Un sistema de archivos provee al usuario con una abstracción que le permitirá crear con facilidad colecciones de datos llamados archivos. Estas colecciones deberán tener los siguientes requisitos o propiedades:
- Existencia a largo tiempo: Los archivos deberán ser almacenados sobre una unidad de almacenamiento y deberán permanecer allí aun cuando el usuario apague el ordenador.
- Deberán tener la capacidad de ser compartidos: Los archivos tendrán nombres que los identifique y deberán poseer permisos de acceso los cuales permitirán el compartimiento controlado entre procesos.
- Deberán poseer una estructura definida: Dependiendo del tipo de sistema de archivos, un archivo deberá poseer una estructura definida y conveniente; permitiendo que los archivos puedan ser organizados en orden jerárquico o en cualquier otro orden para reflejar su relación con otros archivos.
El sistema de archivos como hemos dicho, posee una abstracción que permite realizar varias operaciones sobre los archivos. Entre estas operaciones tenemos:
- Crear un archivo: El usuario o un proceso podrá crear un nuevo archivo el cual tomará una posición dentro de la estructura del sistema de archivos.
- Borrar un archivo: Un archivo podrá ser borrado de la estructura.
- Abrir un archivo: Un proceso podrá abrir un archivo permitiendo el acceso a la información contenida por dicho archivo. El proceso podrá ejecutar varias funciones sobre la información del archivo como leer, escribir, reemplazar, etc.
- Cerrar un archivo: Un proceso puede cerrar el archivo dejando atrás los privilegios de acceder a dicho archivo.
- Leer: Un proceso podrá leer parte de la información contenida en un archivo
- Escribir: Un proceso podrá añadir o reemplazar información en un archivo.
Los sistemas de archivos también mantienen una estructura de atributos asociada con cada uno de los archivos la cual provee información sobre la situación actual de un archivo, quien es su dueño, el tamaño del archivo, cuando fue creado, cuando fue modificado, privilegios de acceso, entre otros.
Funciones del Sistema de Archivos.
Fig. 5.1.4 Manipulación de archivos.
Fig. 5.1.4 Manipulación de archivos.
Los usuarios deben poder crear, modificar y borrar archivos como se muestra en la Fig. 5.1.4.
Se deben poder compartir los archivos de una manera cuidadosamente controlada.
El mecanismo encargado de compartir los archivos debe proporcionar varios tipos de acceso controlado:
Se deben poder compartir los archivos de una manera cuidadosamente controlada.
El mecanismo encargado de compartir los archivos debe proporcionar varios tipos de acceso controlado:
- Ej.: “Acceso de Lectura” , “Acceso de Escritura” , “Acceso de Ejecución” , varias combinaciones de estos, etc.
Se debe poder estructurar los archivos de la manera más apropiada a cada aplicación.
Los usuarios deben poder ordenar la transferencia de información entre archivos.
Se deben proporcionar posibilidades de “respaldo” y “recuperación” para prevenirse contra:
Los usuarios deben poder ordenar la transferencia de información entre archivos.
Se deben proporcionar posibilidades de “respaldo” y “recuperación” para prevenirse contra:
- La pérdida accidental de información.
- La destrucción maliciosa de información.
Se debe poder referenciar a los archivos mediante “Nombres Simbólicos” , brindando “Independencia de Dispositivos” .
En ambientes sensibles, el sistema de archivos debe proporcionar posibilidades de “Cifrado” y “Descifrado”.
El sistema de archivos debe brindar una interfase favorable al usuario:
En ambientes sensibles, el sistema de archivos debe proporcionar posibilidades de “Cifrado” y “Descifrado”.
El sistema de archivos debe brindar una interfase favorable al usuario:
- Debe suministrar una “visión lógica” de los datos y de las funciones que serán ejecutadas, en vez de una “visión física”.
- El usuario no debe tener que preocuparse por:
- Los dispositivos particulares.
- Dónde serán almacenados los datos.
- El formato de los datos en los dispositivos.
- Los medios físicos de la transferencia de datos hacia y desde los dispositivos.
5.2 Archivos reales y virtuales

Archivo Virtual y Archivo Real

Un archivo virtual (Fig.5.2.1), es un archivo de uso temporal que es utilizado por los procesos del sistema mientras se están ejecutando dichos procesos. Estos archivos se crean durante la ejecución de un sistema y los utiliza para el almacenamiento de información, intercambio y organización mientras se ejecuta el sistema (Fig. 5.2.2), su tamaño es muy variable y terminan al detener la ejecución del sistema, muchos de ellos son borrados, por ejemplo, los archivos *.tmp (Fig. 5.2.3) .
Se le conoce como archivo virtual, aquel que contiene los datos generados por el usuario.
Un archivo virtual (Fig.5.2.1), es un archivo de uso temporal que es utilizado por los procesos del sistema mientras se están ejecutando dichos procesos. Estos archivos se crean durante la ejecución de un sistema y los utiliza para el almacenamiento de información, intercambio y organización mientras se ejecuta el sistema (Fig. 5.2.2), su tamaño es muy variable y terminan al detener la ejecución del sistema, muchos de ellos son borrados, por ejemplo, los archivos *.tmp (Fig. 5.2.3) .
Se le conoce como archivo virtual, aquel que contiene los datos generados por el usuario.

Fig.5.2.1 Archivo virtual

Fig. 5.2.2 Ejecución del proceso

Fig. 5.2.3 Archivos temporales(*.tmp)
Archivo Real (Fig. 5.2.4) : Es un objeto que contiene programas, datos o cualquier otro elemento.
Un archivo se muestra de manera real, en la información del espacio que ocupa en un disco duro o sistema de almacenamiento, en otras palabras su tamaño en bytes.
Un archivo se muestra de manera real, en la información del espacio que ocupa en un disco duro o sistema de almacenamiento, en otras palabras su tamaño en bytes.





Fig. 5.2.4 Ejemplos de archivos reales
5.3 Componentes de un sistema de archivos
Lo conforman todas aquellas rutinas encargadas de administrar todos los aspectos relacionados con el manejo de Archivos.
En UNIX se define un File System como un sistema de software dedicado a la creación, destrucción, organización y lectura, escritura y control de acceso de los archivos, funcionalmente los componentes de un sistema de archivos son lenguajes de comandos, interpretador de comandos, manejador del almacenamiento secundario, sistema de entrada y salida y mecanismos de respaldo y recuperación.
En general, un Sistema de Archivos está compuesto por: Métodos De Acceso, Administración De Archivos, Administración De Almacenamiento Secundario, Mecanismos De Integridad.
Métodos De Acceso. Se ocupan de la manera en que se tendrá acceso a la información almacenada en el archivo. Ejemplo: Secuencial, Directo, indexado, etc.
Administración De Archivos. Se ocupa de ofrecer los mecanismos para almacenar, compartir y asegurar archivos, así como para hacer referencia a ellos.
Administración De Almacenamiento Secundario. Se ocupa de asignar espacio para los archivos en los dispositivos de almacenamiento secundario. En la siguiente figura se muestra un ejemplo de la administración de espacio en un disco duro.
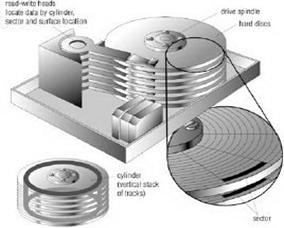
Fig.5.3.1 Administración de almacenamiento en un disco duro.
Mecanismos De Integridad. Se ocupan de garantizar que no se corrompa la información de un archivo, de tal manera que solo la información que deba estar en el, se encuentre ahí.
Mecanismos de Organización Lógica. Contiene las diferentes rutinas y comandos a través de los cuales el usuario podrá estructurar sus archivos virtuales.
Directorio de Identificadores. Convierte los identificadores simbólicos de los archivos en identificadores internos, los cuales apuntarán a su descriptor o a una estructura que permite encontrar el archivo.
Sistemas Teóricos de Archivos. Su objetivo es el de activar y desactivar a través de las rutinas de abrir y cerrar archivos y verifica el modo de acceso.
Mecanismos de Organización Física. Traslada las direcciones lógicas en direcciones físicas correspondientes a las estructuras de memoria secundaria y los buffers en memoria principal necesarios para la transferencia de datos.
Mecanismos de E/S. Por cada petición de acceso al archivo real, este mecanismo genera la secuencia de operaciones elementales de entrada y salida que se necesita.
SCHEDULING E/S. En este nivel es donde se tiene el número de peticiones pendientes así como de las que se están realizando y lleva el control y asignación de tiempo de CPU a las diferentes peticiones de E/S.

Fig. 5.3.2 Ejemplo de un scheduling.
Fig. 5.3.2 Ejemplo de un scheduling.
5.4 Organizacion de Archivos
Se refiere a las diferentes maneras en las que puede ser organizada la información de los archivos, así como las diferentes maneras en que ésta puede ser accesada. Dado que hay 2 niveles de visión de los archivos (físico y lógico), se puede hablar también de 2 aspectos de organización de archivos: Organización de archivos lógicos y de archivos físicos.
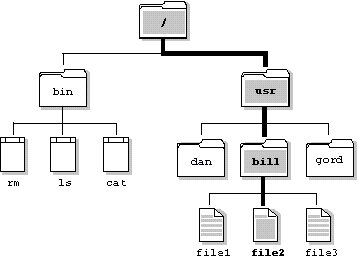
Fig. 5.4.1 Organización de un sistema de archivos utilizando directorios.
El sistema de archivos está relacionado especialmente con la administración del espacio de almacenamiento secundario, fundamentalmente con el almacenamiento de disco.
Una forma de organización de un sistema de archivos puede ser la siguiente:
Esta forma de organización se muestra en la Fig. 5.4.1.
Los nombres de archivos solo necesitan ser únicos dentro de un directorio de usuario dado.
El nombre del sistema para un archivo dado debe ser único para el sistema de archivos.
En sistemas de archivo “jerárquicos” el nombre del sistema para un archivo suele estar formado como el “nombre de la trayectoria” del directorio raíz al archivo.
Organización lógica.
La mayoría de las computadoras organizan los archivos en jerarquías llamadas carpetas, directorios o catálogos . (El concepto es el mismo independientemente de la terminología usada.) Cada carpeta puede contener un número arbitrario de archivos, y también puede contener otras carpetas. Las otras carpetas pueden contener todavía más archivos y carpetas, y así sucesivamente, construyéndose un estructura en árbol en la que una «carpeta raíz» (el nombre varía de una computadora a otra) puede contener cualquier número de niveles de otras carpetas y archivos. A las carpetas se les puede dar nombre exactamente igual que a los archivos (excepto para la carpeta raíz, que a menudo no tiene nombre). El uso de carpetas hace más fácil organizar los archivos de una manera lógica.
La mayor parte de las estructuras de organizaciones alternativas de archivos se encuentran dentro de estas cinco categorías:
Pilas
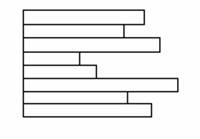
Fig. 5.4.2 Archivo de pilas:Registro de longitud variable. Conjunto variable de campos. Orden cronologico.
Es la forma más fácil de organizar un archivo. Los datos se recogen en el orden en que llegan.
Su objetivo es simplemente acumular una masa de datos y guardarla.
Los registros pueden tener campos diferentes o similares en un orden distinto. Cada campo debe ser autodescriptivo, incluyendo tanto un campo de nombre como el valor. La longitud de cada campo debe indicarse implícitamente con delimitadores, explícitamente incluidos como un subcampo más.
El acceso a los registros se hace por búsquedas exhaustiva y son fáciles de actualizar. Si se quiere encontrar un registro que contiene un campo particular y un valor determinado, es necesario examinar cada registro de la pila hasta encontrar el registro deseado. Si se quieren encontrar todos los registros que contienen un campo particular o que tienen un valor determinado para ese campo, debe buscarse el archivo entero.
Se aplica cuando los datos se recogen o almacenan antes de procesarlos o cuando no son fáciles de organizar. Esta clase de archivo aprovecha bien el espacio cuando los datos almacenados varían en tamaño y estructura. Fuera de estos usos limitados, este tipo de archivos no se adapta a la mayoría de las aplicaciones.
Archivos secuenciales

Fig. 5.4.3 Archivo secuencial: Registro de longitud fija. Conjunto fijo de campos en orden constante. Orden secuencial por el campo clave.
Es la forma más común de estructura de archivos.
Se emplea un formato fijo para los registros, son de la misma longitud y constan del mismo número de campos de tamaño fijo con un orden determinado.
Se necesita almacenar los valores de cada campo; el nombre del campo y la longitud de cada uno son atributos de la estructura del archivo. Cada registro tiene un campo clave que lo identifica (generalmente es el primero de cada registro). Los registros se almacenan en secuencia por la clave.
Se utilizan normalmente en aplicaciones de procesos por lotes, ya que es la única organización de archivos que se puede guardar tanto en cintas como en discos.
Para las aplicaciones interactivas que incluyen peticiones o actualizaciones de registros individuales, los archivos secuenciales no son óptimos. El acceso requiere una búsqueda secuencial de correspondencias con la clave. Si el archivo entero o gran parte de él pueden traerse a la memoria principal de una sola vez, se podrán aplicar técnicas de búsquedas más eficientes. Al acceder un registro de un archivo secuencial grande, se produce un procesamiento extra y un retardo considerable.
La organización física del archivo en una cinta o disco se corresponde exactamente con la organización lógica del archivo, por lo tanto el procedimiento habitual es ubicar los nuevos registros en un archivo de pila separado, es llamado archivo de registro o archivo de transacciones .
Una alternativa es organizar físicamente el archivo secuencial como una lista enlazada, en cada bloque físico se almacena uno o más registros y cada bloque del disco contiene un puntero al bloque siguiente. La inserción de un nuevo registro implica la manipulación de puntero, pero no requiere que el nuevo registro ocupe una posición particular del bloque físico.
Archivos secuenciales indexados

Fig. 5.4.4 Archivo secuancial indexado.
Los registros se organizan en una secuencia basada en un campo clave presentando dos características, un índice del archivo para soportar los accesos aleatorios y un archivo de desbordamiento. El índice proporciona una capacidad de búsqueda para llagar rápidamente al registro deseado y el archivo de desbordamiento es similar al archivo de registros usado en un archivo secuencial, pero está integrado de forma que los archivos de desbordamiento se ubiquen siguiendo un puntero desde su registro predecesor.
La estructura más simple tiene como índice un archivo secuencial simple, cada registro del archivo índice tiene dos campos, un campo clave igual al del archivo principal y un puntero al archivo principal. Para encontrar un campo especifico se busca en el índice hasta encontrar el valor mayor de la clave que es iguale o precede al valor deseado de la clave, la búsqueda continua en el archivo principal a partir de la posición que indique el puntero.
Cada registro del archivo principal tiene un campo adicional que es un puntero al archivo de desbordamiento. Cuando se inserta un nuevo registro al archivo, también se añade al archivo de desbordamiento. El registro del archivo principal que precede inmediatamente al nuevo registro según la secuencia lógica se actualiza con un puntero del registro nuevo en el archivo de desbordamiento, si el registro inmediatamente anterior está también en el archivo de desbordamiento se actualizará el puntero en el registro.
Para procesar secuencialmente un archivo completo los registros del archivo principal se procesarán en secuencia hasta encontrar un puntero al archivo de desbordamiento, el acceso continua en el archivo de desbordamiento hasta que encuentra un puntero nulo, entonces renueva el acceso donde se abandonó en el archivo principal.
Archivos indexados
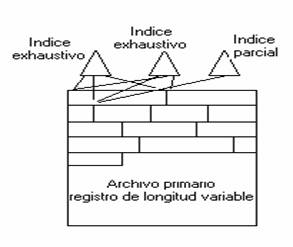
Fig. 5.4.5 Archivo indexado.
A los registros se accede solo a través de sus índices. No hay resticción en la ubicación de los registros, al menos un índice contiene un puntero a cada registro y pueden emplearse registros de longitud variable.
Se suelen utilizar dos tipos de índices, uno exhaustivo que contiene una entrada para cada registro del archivo principal y se organiza como un archivo secuencial para facilitar la búsqueda, el otro índice es parcial que contiene entrada a los registros donde esté el campo de interés.
Con registro de longitud variable, algunos registros no contendrán todos los campos y cuando se añade un registro al archivo principal, todos los archivos de índices deben actualizarse.
Archivos directos o de dispersión
Explotan la capacidad de los discos para acceder directamente a cualquier bloque de dirección conocida.
Se requiere un campo clave en cada registro.
Los archivos directos son muy usados donde se necesita un acceso muy rápido, donde se usan registros de longitud fija y donde siempre se accede a los registros de una vez.
Organización física.
Los datos son arreglados por su adyacencia física, es decir, de acuerdo con el dispositivo de almacenamiento secundario. Los registros son de tamaño fijo o de tamaño variable y pueden organizarse de varias formas para constituir archivos físicos.
Cinta magnética. 
Fig. 5.4.6 Cintas magnéticas
En este dispositivo el archivo físico esta formado por un conjunto de registros físicos, y los bloques están organizados en forma consecutiva, ya que se asigna en igual forma.
Además tales registros puede contener etiquetas que permitan un mayor control sobre los datos almacenados, y son las siguientes:
- Etiqueta de volumen.- Contiene información que permite identificar la cinta, el nombre del propietario y cualquier información general requerida.
- Etiqueta de archivo.- Se utilizan por pares para indicar el inicio y fin del archivo, contiene información acerca del nombre del archivo, fecha de creación.
- Etiqueta de usuario.- Sirven para guardar información adicional de importancia para el usuario; no son procesados por el sistema operativo.
Discos Magnéticos.
Fig. 5.4.7 Discos magnéticos
El archivo físico en un disco es una colección de registros físicos de igual tamaño, los cuales pueden estar organizados en forma consecutiva, ligada o con una tabla de mapeo.
En la organización contigua, el archivo utiliza registros físicos contiguos, siguiendo la secuencia normal de direcciones.
La organización encadenada consiste un conjunto de bloques, cada uno de los cuales tiene un campo destinado para indicar la dirección del siguiente registro, o sea, para lo que se ha llamado enlace o liga.
Otra forma de organización es la tabla de mapeo que consiste en una tabla de apuntadores a los registros físicos que forman el archivo.
La organización física de un archivo en el almacenamiento secundario depende de la estrategia de agrupación y de la estrategia de asignación de archivos.
Para elegir una organización de archivos se deben tener en cuenta ciertos criterios:
Si un archivo va a procesar solamente por lotes, accediendo cada vez a todos los registros, entonces el acceso rápido para la recuperación de un único registro es una preocupación mínima. Un archivo almacenado en CD-ROM nunca será actualizado, por lo que la facilidad de actualización no se considera. Para la economía de almacenamiento , debería existir una mínima redundancia de los datos, ésta redundancia es el medio fundamental para incrementar la velocidad de acceso a los datos.
Este tipo de organización muestra a su vez, 2 aspectos importantes: Métodos De Asignación De Espacio Libre y Asignación De Espacio De Almacenamiento Del Archivo.
METODOS DE ASIGNACION DE ESPACIO LIBRE
Un método de asignación de espacio libre determina la manera en que un Sistema Operativo controla los lugares del disco que no están siendo ocupados.
Para el control del espacio libre se puede utilizar como base alguno de los métodos teóricos: Vector de Bits, Lista Ligada, Por Agrupacion y por Contador.
VECTOR DE BITS
Se tiene un arreglo de bits, el número de bits que tiene, representa cada sector del disco, o sea que si los sectores 10 y 11 están ocupados su representacion será:

Fig. 5.4.8 Ejemplo de un vector de bits.
LISTA LIGADA
Existe una cabeceraen la que se tiene la direccion del primer sector vacio, ese sector a su vez, tiene un apuntador al siguiente bloque, y así sucesivamente hasta que se encuentre una marca indicando que ya no hay espacio libre, tal y como se muestra en la siguiente figura.
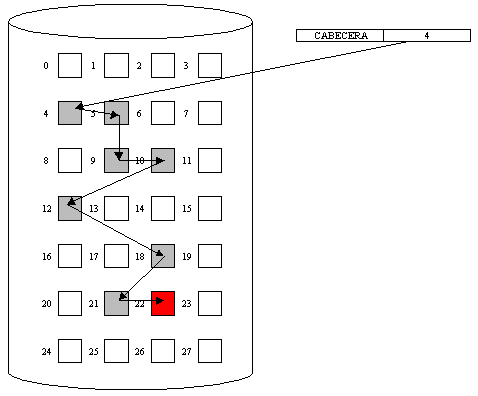
Fig. 5.4.9 Ejemplo de una lista ligada
POR AGRUPACION
Es similar a la lista ligada, solo que en este se tiene por cada sector, un grupo de apuntadores a varios espacios vacios, al final de cada bloque se tiene un apuntador a otro grupo de apuntadores, observe la figura.

Fig. 5.4.10 Ejemplo de asignación por agrupación.
POR CONTADOR
Aqui, por cada conjunto de bloques contiguos que estén vacios, se tiene por cada apuntador, un número de inicio y el tamaño del grupo de sectores vacios.
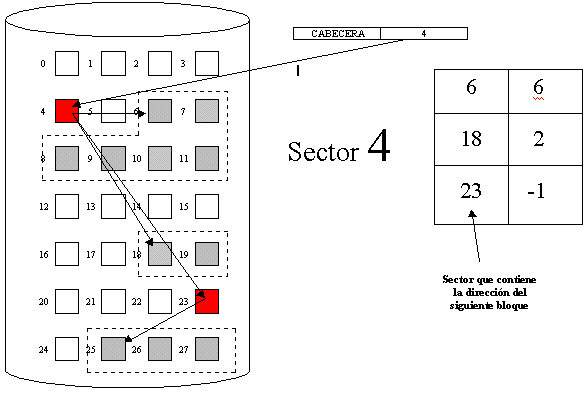
Fig. 5.4.11 Ejemplo de asignación por contador.
MÉTODOS DE ASIGNACIÓN DE ESPACIO EN DISCO.
Un método de asignación de espacio en disco determina la manera en que un Sistema Operativo controla los lugares del disco ocupados por cada archivo de datos. Se debe controlar básicamente la identificación del archivo, sector de inicio y sector final.
Para el control del espacio ocupado en disco se puede utilizar como base alguno de los métodos teóricos: Asignación Contigua, Asignación Ligada, Asignación Indexada.
ASIGNACIÓN CONTIGUA.
Este método consiste en asignar el espacio en disco de tal manera que las direcciones de todos losbloques correspondientes a un archivo definen un orden lineal. Por ejemplo:
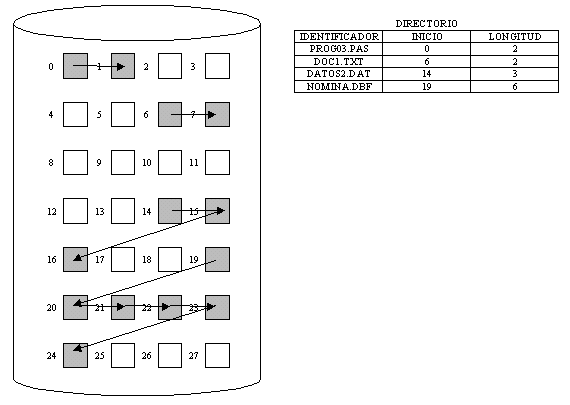
Fig. 5.4.12 Ejemplo de asignación contigua.
ASIGNACIÓN LIGADA
En este método, cada archivo es una lista ligada de bloques de disco. En el directorio hay un apuntador al bloque de inicio y un apuntador al bloque final para cada archivo. En cada uno de los bloques donde se encuentra un archivo hay un apuntador al siguiente bloque de la lista. Por ejemplo:
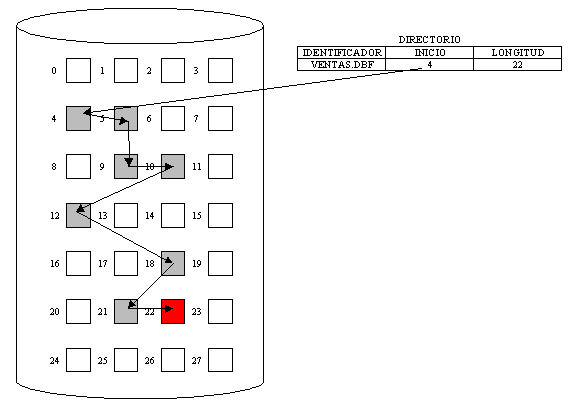
Fig. 5.4.13 Ejemplo de asignación ligada
ASIGNACIÓN INDEXADA
Como ya se vio, la asignación ligada resuelve problemas de fragmentación externa, sin embargo, laasignación ligada no soporta eficientemente el acceso directo a los archivos. La asignación indexada resuelve este problema poniendo todos los apuntadores en una sola localidad: El bloque índice .
Cada archivo tiene su bloque índice, El cual es un arreglo de direcciones de bloques de disco.
La i-ésima entrada en el bloque índice apunta al i-ésimo bloque que conforma el archivo. En el directorio se controla la dirección del bloque índice de cada archivo, por ejemplo:
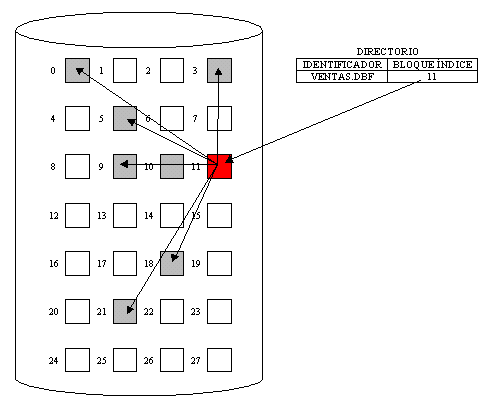
Fig. 5.4.14 Ejemplo de asignación indexada.
|
5.5 Mecanismos de acceso a los archivos

Existen varios mecanismos para acceder los archivos: Directorios, descriptores de archivos, mecanismos de control de acceso y procedimientos para abrir y cerrar archivos.
Descriptores de archivos.
El descriptor de archivos o bloque de control de archivos es un bloque de control que contiene información que el sistema necesita para administrar un archivo.
Es una estructura muy dependiente del sistema.
Puede incluir la siguiente información:
Los descriptores de archivos suelen mantenerse en el almacenamiento secundario; se pasan al almacenamiento primario al abrir el archivo.
El descriptor de archivos es controlado por el sistema de archivos ; el usuario puede no hacer referencia directa a él.
A cada uno de los archivos se le asigna un descriptor el cual contendrá toda la información que necesitará el sistema de archivos para ejecutar con él los comandos que se le soliciten. El descriptor se mantendrá en memoria principal desde que el archivo es abierto hasta que sea cerrado, y debe tener al menos la siguiente información, identificación del archivo, lugar de almacenamiento, información del modo de acceso.
Identificación del archivo. Consiste de dos partes que es el nombre simbólico que es el que le da el usuario y un identificador interno que es asignado por el sistema operativo (número). Lugar de almacenamiento así como el tamaño del archivo. Modo de acceso. Se debe indicar en forma explícita quien puede accesar el archivo y conque derecho.
Fig. 5.5.1 Ejemplo ilustrativo del control de acceso
Mecanismo de control de acceso.
Control de un sistema de información especializado en detectar los intectos de acceso, permitiendo el paso de las entidades autorizadas, y denegando el paso a todas las demás. Involucra medios técnicos y procedimientos operativos.
Mecanismo que en función de la identificación ya autenticada permite acceder a datos o recursos.
Los Directorios son utilizados por el sistema operativo para llevar un registro de los archivos que incluye el nombre, los atributos y las direcciones en disco donde se almacenan los datos del archivo referenciado.
Open (abrir): antes de utilizar un archivo, un proceso debe abrirlo. La finalidad es permitir que el sistema traslade los atributos y la lista de direcciones en disco a la memoria principal para un rápido acceso en llamadas posteriores.
Close (cerrar): cuando concluyen los accesos, los atributos y direcciones del disco ya no son necesarios, por lo que el archivo debe cerrarse y liberar la tabla de espacio interno.
|
5.6 Manejo de espacio en memoria secundaria
A diferencia de la Memoria Principal la Memoria Secundaria , auxiliar, masiva, externa no es tan veloz pero tiene gran capacidad para almacenar información en dispositivos tales como discos, cintas magnéticas, discos ópticos. Frecuentemente los datos y programas se graban en la Memoria Secundaria , de esta forma, cuando se ejecuta varias veces un programa o se utilicen repetidamente unos datos, no es necesario darlos de nuevo a través del dispositivo de entrada.
    
Fig. 5.6.1 Ejemplos de Memoria Secundaria
En la Memoria Secundaria un archivo consta de un conjunto de bloques (correspondiente a la cantidad de información que se transfiere físicamente en cada operación de acceso (lectura o escritura).
El Sistema Operativo o Sistema de Gestión de Archivos es el encargado de la asignación de bloques a archivos, de lo que surgen dos cuestiones, en primer lugar, debe asignarle el espacio de Memoria Secundaria a los archivos y, en segundo lugar, es necesario guardar constancia del espacio disponible para asignar.
El sistema de archivos se ocupa primordialmente de administrar el espacio de almacenamiento secundario, sobre todo el espacio en disco. El manejo del espacio libre en disco se lleva a cabo de la siguiente manera:
Vector de bits. El espacio libre en disco es frecuentemente implementado como un mapa de bits, donde cada block es representado por un bit y si el bloc es libre el bit es cero de lo contrario está asignado.11000111
Lista ligada. Una lista ligada de todos los blocks libres. Otra implantación se consigue guardando la dirección del primer block libre y el número de los blocks libres contiguos que le siguen. Cada entrada de la lista de espacio libre consiste de una dirección de disco y un contador (por conteo).
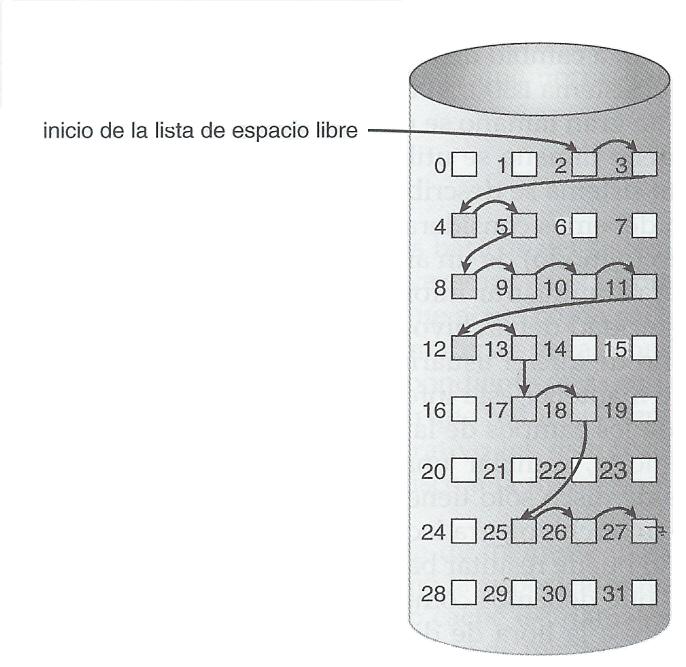
Fig. 5.6.2 Lista de espacio libre enlazada en el disco.
Por agrupación. Se almacena la dirección en n blocks libres en el primer block libre y el último contiene la dirección de otro block que contiene la dirección de otros blocks libres.
Para manejar los espacios en disco existen los siguientes métodos:
? Contiguos
? Contiguos. Esta asignación requiere que cada archivo ocupe un conjunto de direcciones contiguas en el disco, su asignación es definida por la dirección del primer bloc y la longitud del archivo.
Cuando se crea un archivo se le asigna un único conjunto contiguo de bloques, esta es un estrategia de asignación previa que emplea secciones de tamaño variable. La tabla de asignación de archivos necesita solo una entrada por cada archivo y que muestre el bloque de comienzo y la longitud del archivo. La asignación contigua es la mejor para un archivo secuencial.
La asignación contigua presenta algunos problemas, como la fragmentación externa. Lo que hace difícil encontrar bloques contiguos de espacio de tamaño suficiente., lo que lleva a ejecutar un algoritmo de compactación para libera el espacio adicional en el disco.
? Asignación ligada o encadenada. Cada archivo es una lista ligada de blocks y el directorio contiene un apuntador al primer bloc y al último.
La asignación se hace con bloques individuales, cada bloque contendrá un puntero al siguiente bloque de la cadena. La tabla de asignación de archivos necesita una sola entrada por cada archivo que muestre el bloque de comienzo y la longitud del mismo, cualquier bloque puede añadirse a la cadena. No hay que preocuparse por la fragmentación externa porque solo se necesita un bloque cada vez.
Una consecuencia del encadenamiento es que no hay cabida para el principio de cercanía, si es necesario traer varios bloques de un archivo al mismo tiempo, se necesita una serie de accesos a partes diferentes del disco por lo que se debe ejecutar un algoritmo de compactación para liberar el espacio adicional en el disco.
? Asignación Indexada. Cada archivo tiene su propio bloc de índice el cual es un arreglo de direcciones de bloc.
En esta asignación la tabla de asignación de archivos contiene un índice separado de un nivel para cada archivo: el índice posee una entrada para cada sección asignada al archivo. Normalmente, los índices no están almacenados físicamente como parte de la tabla de asignación de archivos. Mas exactamente el índice de archivo se guardara en un bloque aparte y la entrada del archivo en la entrada de asignación apuntara a dicho bloque.
La asignación puede hacerse por bloques de tamaño fijo, O en secciones de tamaño variable. La asignación por bloques elimina la fragmentación externa, mientras que la asignación por secciones de tamaño variable mejora la cercanía. En cualquier caso, los archivos pueden concentrarse en zonas cercanas de cuando en cuando. La concentración reduce el tamaño del índice en el caso de secciones de tamaño variable, pero no en el caso de asignación por bloques.
La asignación indexada soporta tanto el acceso secuencial como el acceso directo a los archivos y por ello se ha convertido en la forma más popular de asignación de archivos.
En un sistema de cómputo, los elementos que se declaran para almacenamiento son los Fyle System. Cuándo existe una solicitud de almacenamiento o manejo de bloc libres en un file system surge una interrogante ¿cómo atenderlas? esto se lleva a cabo mediante una planificación de discos y para esto existen las siguientes políticas de planificación.
|
5.7 Modelo jeraquico
| Directorios |
| El directorio contiene un conjunto de datos por cada archivo referenciado. 
Fig. 5.7.1 Ejemplo de directorio jerárquico
Una posibilidad es que el directorio contenga por cada archivo referenciado:
Fig. 5.7.2 Representación gráfica de un directorio jerárquico.
Al abrir un archivo el S. O.:
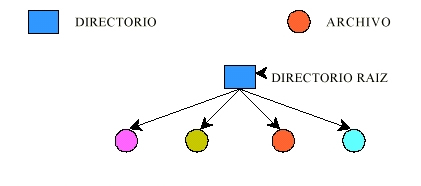 Fig. 5.7.3 Un solo directorio compartifo por todos los usuarios 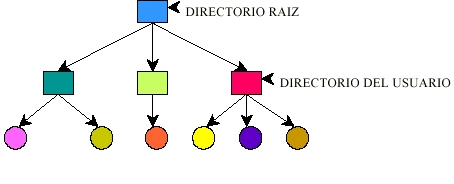 Fig. 5.7.4 Un directorio por usuario 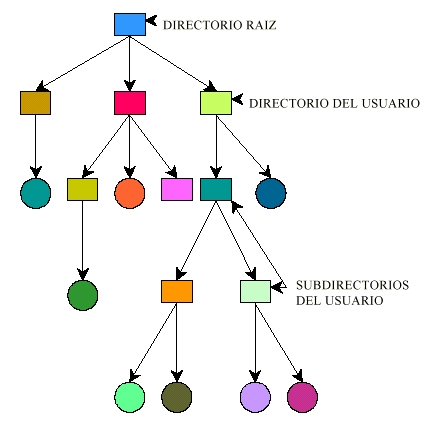 Fig. 5.7.5 Un árbol arbitrario por usuario |
5.8 Mecanismo de recuperacion en caso de falla
| Recuperación
Los archivos y directorios se mantienen tanto en memoria principal como en disco, y debe tener. Se cuidado para que los fallos del sistema no provoquen una pérdida de datos o una incoherencia en los mismos.
Comprobación de coherencia.
Como hemos explicado en la Sección 11.3, parte de la información de directorios se almacena en la memoria principal (o en caché) para acelerar el acceso. La información de directorios en11a memoria principal está, generalmente, más actualizada que la correspondiente información en el disco, porque la información de directorios almacenada en caché no se escribe necesariamente en el disco nada más producirse la actualización.
Considere, entonces, el posible ejemplo de un fallo de la computadora. El contenido de la caché y de los búferes, así como de las operaciones de E/S que se estuvieran realizando en ese momento, pueden perderse, y con él se perderán los cambios realizados en los directorios correspondientes a los archivos abiertos. Dicho suceso puede dejar el sistema de archivos en un estado incoherente. El estado real de algunos archivos no será el que se describe en la estructura de directorios.
Con frecuencia, suele ejecutarse un programa especial durante el reinicio para comprobar las posibles incoherencias del disco y corregidas.
El comprobador de coherencia (un programa del sistema tal como fsck en UNIX o chkdsk en MS-DOS), compara los datos de la estructura de directorios con los bloques de datos del disco y trata de corregir todas las incoherencias que detecte. Los algoritmos de asignación y de gestión del espacio libre dictan los tipos de problemas que el comprobador puede tratar de detectar y dictan también el grado de éxito que el comprobador puede tener en esta tarea. Por ejemplo, si se utiliza un sistema de asignación enlazada y existe un enlace entre cada bloque y el siguiente, puede reconstruirse el archivo completo a partir de los bloques de datos y volver a crear la estructura de directorios. Por el contrario, la pérdida de una entrada de directorio en un sistema de asignación indexada puede ser desastrosa, porque los bloques de datos no tienen ningún conocimiento acerca de los demás bloques de datos del archivo. Por esta razón, UNIX almacena en caché las entradas de directorio para las lecturas, pero todas las escrituras de datos que provoquen algún cambio en la asignación de espacio o en algún otro tipo de metadato se realizan síncronamente, antes de escribir los correspondientes bloques de datos. Por supuesto, también pueden aparecer problemas si se interrumpe una escritura síncrona debido a un fallo catastrófico.
 
Fig. 5.8.1 Errores
La perdida de la información es uno de los factores que se le debe de dar mayor importancia, por la sencilla razón de que al perder información se puede perder lo que no nos podemos imaginar en cuanto a la misma y ocasionar perdidas hasta hablar de una gran cantidad de dinero. Para solucionar este o estos problemas todo sistema operativo cuenta con al menos una herramienta de software que nos permite recuperar información perdida hasta cierta medida, esto obedece de acuerdo al daño causado o los daños. Si el sistema no cuenta con la herramienta necesaria, deberá adquirirse el software apropiado de algún fabricante especializado en el ramo, por ejemplo Norton.
Es necesario proteger la información alojada en el sistema de archivos, efectuando los resguardos correspondientes.
De esta manera se evitan las consecuencias generalmente catastróficas de la pérdida de los sistemas de archivos.
Las pérdidas se pueden deber a problemas de hardware, software, hechos externos, etc.
Manejo de un bloque defectuoso:
Se utilizan soluciones por hardware y por software.
La solución en hardware:
La solución en software:
Respaldos (copias de seguridad o de back-up):

Fig. 5.8.2 Es necesario realizar respaldos para asegurar información
Es muy importante respaldar los archivos con frecuencia.
Los discos magnéticos fallan en ocasiones y es necesario tener cuidado para garantizar que los datos perdidos debido a esos fallos no se pierdan para siempre. Con este fin, pueden utilizarse programas del sistema para realizar una copia de seguridad de los datos del disco en otro dispositivo de almacenamiento, como por ejemplo un disquete, una cinta magnética, un disco óptico incluso otro disco duro. La recuperación de la pérdida de un archivo individual o de un disco completo puede ser entonces, simplemente, una cuestión de restaurar los datos a partir de la copia de seguridad.
Los respaldos pueden consistir en efectuar copias completas del contenido de los discos (flexibles o rígidos).
Una estrategia de respaldo consiste en dividir los discos en áreas de datos y áreas de respaldo , utilizándolas de a pares:
Otra estrategia es el vaciado por incrementos o respaldo incremental :
Podemos escribir las copias de seguridad correspondientes al nuevo ciclo sobre el conjunto anterior de soportes físicos o en un nuevo conjunto de soportes de copia de seguridad. De esta forma, podemos restaurar un disco completo comenzando la restauración con la copia de seguridad completa y continuando con cada una de las copias de seguridad incrementales. Por supuesto, cuanto mayor sea el valor de N, más cintas o discos habrá que leer para efectuar una restauración completa. Una ventaja adicional de este ciclo de copia de seguridad es que podemos restaurar cualquier archivo que haya sido borrado accidentalmente durante ese ciclo, extrayendo el archivo borrado de la copia de seguridad del día anterior. La longitud del ciclo será un compromiso entre la cantidad de soportes físicos de copia de seguridad requeridos y el número de días pasados a partir de los cuales podamos realizar una restauración. Para reducir el número de cintas que haya que leer para efectuar una restauración, una opción consiste en realizar una copia de seguridad completa y luego copiar cada día todos los archivos que hayan cambiado desde la última copia de seguridad completa. De esta forma, puede realizarse la restauración utilizando sólo la copia de seguridad incremental más reciente y la copia de seguridad completa, no necesitándose ninguna otra copia de seguridad incremental. El compromiso inherente a este sistema es que el número de archivos modificado se incrementa a diario, por lo que cada copia de seguridad incremental sucesiva contiene más archivos y requiere más espacio en el soporte de copia de seguridad.• Día 1. Copiar en el soporte de copia de seguridad todos los archivos del disco. Esto se denomina copia de seguridad completa.
Consistencia del sistema de archivos:
Muchos sistemas de archivos leen bloques, los modifican y escriben en ellos después.
Si el sistema falla antes de escribir en los bloques modificados, el sistema de archivos puede quedar en un “estado inconsistente”.
La inconsistencia es particularmente crítica si alguno de los bloques afectados son:
La mayoría de los sistemas dispone de un programa utilitario que verifica la consistencia del sistema de archivos:
Generalmente los utilitarios utilizan dos tablas:
Si un bloque no aparece en ninguna de las tablas se trata de una falla llamada bloque faltante:
También podría detectarse la situación de falla debida a un bloque referenciado dos veces en la tabla de bloques libres:
Una falla muy grave es que el mismo bloque de datos aparezca referenciado dos o más veces en la tabla de bloques en uso:
Otro error posible es que un bloque esté en la tabla de bloques en uso y en la tabla de bloques libres:
Las verificaciones de directorios incluyen controles como:
Una posible falla es que el contador de enlaces sea mayor que el número de entradas del directorio:
Otro tipo de error es potencialmente catastrófico:

También se pueden hacer verificaciones heurísticas , por ej.:
Se debería informar como sospechosos aquellos directorios con excesivas entradas, por ej., más de mil.
|
No hay comentarios:
Publicar un comentario